Introduction
As deep learning models become increasingly integrated into critical systems, the security implications of these AI models demand closer analysis. While much attention has focused on adversarial attacks and model poisoning, a more subtle threat lurks in the architecture of neural networks themselves: tensor steganography. This technique allows malicious actors to embed hidden payloads directly within model weights without significantly affecting performance, creating a potential vector for distributing malware that bypasses traditional security measures.
In this article, I’ll explore how tensor steganography works, demonstrate its feasibility in popular models like ResNet18, and explain why security professionals and ML engineers should be concerned about this emerging threat vector.
What is Tensor Steganography?
Steganography is the practice of hiding information within other non-secret data or a physical object to avoid detection. Unlike encryption, which makes data unreadable but visible, steganography conceals the very existence of the hidden data.
Tensor steganography applies this concept to neural networks by embedding data in the least significant bits of the floating-point values that make up model weights. These minor alterations are virtually undetectable through casual inspection and have minimal impact on model performance, making them an ideal hiding place for malicious code.
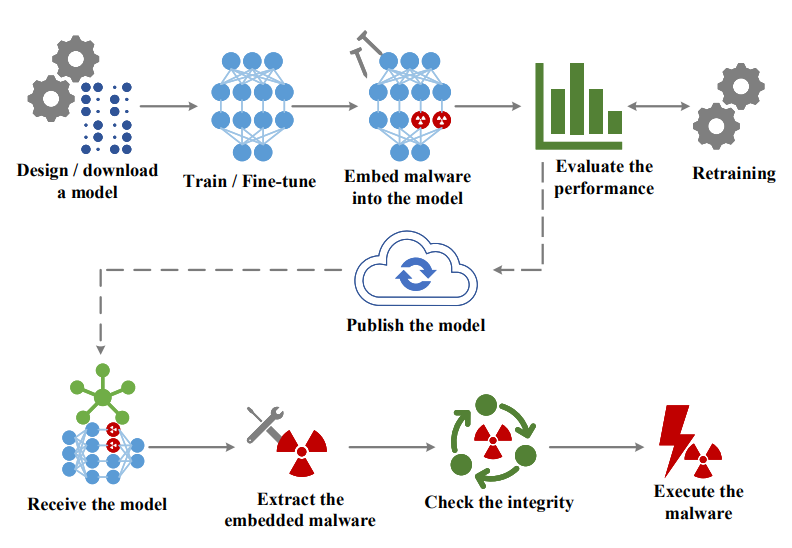
Feasibility Analysis: The ResNet18 Case Study
To understand the risk, let’s analyze the capacity for hidden data in a relatively small model like ResNet18. The largest convolutional layer in ResNet18 contains approximately 9.4MB of floating-point values . By manipulating just the least significant bits of each float’s mantissa, we can embed surprising amounts of data:
| Bits Modified Per Float | Storage Capacity |
|---|---|
| 1-bit | 294.9 kB |
| 2-bits | 589.8 kB |
| 3-bits | 884.7 kB |
| 4-bits | 1.2 MB |
| 5-bits | 1.5 MB |
| 6-bits | 1.8 MB |
| 7-bits | 2.1 MB |
| 8-bits | 2.4 MB |
 This analysis reveals that even a modest model like ResNet18 can conceal up to 2.4MB of data by modifying just 8 bits per float in a single layer. Larger models commonly used in production environments could potentially hide much more — up to 9MB of malicious code using only 3 bits per float in a single layer.
This analysis reveals that even a modest model like ResNet18 can conceal up to 2.4MB of data by modifying just 8 bits per float in a single layer. Larger models commonly used in production environments could potentially hide much more — up to 9MB of malicious code using only 3 bits per float in a single layer.
Implementation: How Tensor Steganography Works
Below is a Python implementation that demonstrates how to embed an arbitrary payload into a PyTorch model using steganography. This is a simple and naive example for illustrative purposes. In practice, a malicious actor could employ far more sophisticated techniques, making the detection and analysis of such hidden data significantly more challenging.
1. Import Dependencies
We first import the required libraries:
| |
2. Function Definition and Validations
We define the function and validate the bit-depth parameter n:
| |
3. Load the Model
We load the model :
| |
4. Read & Prepare the Payload
Before embedding, we format the payload to include:
- File size (so it can be reconstructed correctly)
- SHA-256 hash (for integrity verification)
- The actual payload data
| |
5. Convert Payload to Bit Stream
| |
6. Embed the Bits into the Model’s Tensors
| |
7. Save the Modified Model
The model is automatically saved inside the loop when the entire payload is embedded. If embedding fails, we return False.
N.B : This code includes a verification mechanism (SHA256 hash) to ensure the payload can be correctly extracted later. The payload format consists of the data size, a hash for verification, and the actual content.
Below is the full script in one place for convenience:
| |
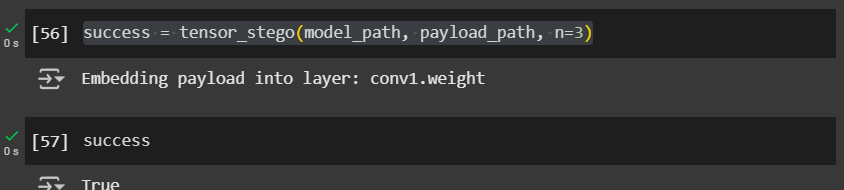
Here’s a test snippet using ResNet18 to verify tensor_stego() :
| |
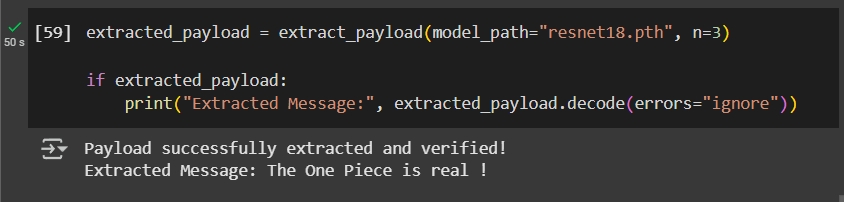
Here’s the reverse function to extract the hidden payload from the PyTorch model. This function will:
- Load the model from the given path.
- Extract the LSBs of the weights to reconstruct the payload.
- Verify the extracted payload by checking its SHA-256 hash.
| |
| |
Security Implications
The ability to hide executable code within model weights presents several concerning security implications:
- Bypassing Security Scanning: Traditional malware detection tools don’t inspect ML model weights, allowing embedded malicious code to evade detection.
- Supply Chain Attacks: Pre-trained models downloaded from public repositories could contain hidden payloads that activate when the model is loaded.
- Persistent Backdoors: Since model weights are rarely inspected or modified after deployment, embedded code could remain undetected for extended periods.
- Execution Pathways: Concealing data within tensors is only the first step. The real threat emerges when this hidden payload is automatically extracted and executed, potentially exploiting vulnerabilities in how ML frameworks deserialize and handle model parameters. Prior research has demonstrated how adversaries can craft malicious models that trigger arbitrary code execution upon loading, bridging the gap between passive data hiding and active system compromise. For those interested in the practical exploitation of this vulnerability, this article provides a detailed breakdown of real-world attack scenarios, including a concrete example of how serialization flaws in PyTorch models can be leveraged for execution.
Defensive Measures
As a data professional responsible for model security, consider implementing these comprehensive protective measures:
- Source Verification: Only use models from trusted sources with verified signatures. Implement model signing as a means of performing integrity checking to detect tampering and corruption.
- Weight Analysis: Develop tools to analyze the distribution of least significant bits in model weights, which may reveal statistical anomalies indicating hidden data. Techniques such as entropy and Z-score analysis can help detect low-entropy payloads, though encrypted payloads remain challenging to identify.
- Sandboxed Loading: Load models in isolated environments with limited permissions to prevent potential code execution. This is especially critical when using pre-trained models downloaded from the internet, as current anti-malware solutions may not detect all code execution techniques.
- Security Scanning Tools: Utilize specialized tools like TrailOfBits’ Fickling to detect simple attempts to exploit ML serialization formats. Monitor repositories like HuggingFace that have implemented security scanners for user-supplied models.
- Format Selection: Choose storage formats that offer enhanced security by avoiding data deserialization flaws, which are particularly vulnerable to exploitation.
- EDR Solutions: Deploy and properly tune Endpoint Detection and Response solutions to gain better insight into attacks as they occur, particularly for detecting advanced payloads delivered via ML models.
- Regular Security Audits: Conduct periodic security audits of your AI infrastructure, focusing on the integrity of deployed models and potential vulnerabilities in your ML pipeline.
Conclusion
Tensor steganography represents a sophisticated attack vector that could transform seemingly benign deep learning models into vehicles for malware distribution. As ML systems continue to proliferate across critical infrastructure, security professionals must expand their threat models to include these novel attack vectors.
The research demonstrates that even small models contain sufficient capacity to hide substantial malicious payloads with minimal impact on model performance. As larger models become standard, this capacity increases significantly—amplifying the potential threat.
For organizations developing or deploying ML systems, understanding and mitigating these risks should become an essential component of AI security protocols. The intersection of deep learning and cybersecurity continues to reveal new challenges that require vigilance and innovative defensive approaches.
For a more comprehensive understanding of this threat, I encourage readers to explore the references which provides detailed explanations of payload exploitation techniques, practical demonstrations, and extensive references. This in-depth resources offers security professionals the technical insights needed to develop robust defensive measures against this type of attacks.
References :
- Weaponizing ML Models with Ransomware
- StegoNet: Turn Deep Neural Network into a Stegomalware
- EvilModel: Hiding Malware Inside of Neural Network Models
- Sleeper Agent: Scalable Hidden Trigger Backdoors for Neural Networks Trained from Scratch
- https://www.darkreading.com/application-security/hugging-face-ai-platform-100-malicious-code-execution-models
- https://medium.com/@limbagoa/securing-the-ai-supply-chain-051f8d43c5c4
- https://www.techrepublic.com/article/pytorch-ml-compromised/